Random in Spark: the Hidden Dangers
Using random in Spark jobs is a dangerous practice. Most of the time, it will work fine, but there are corner cases where you can quietly get incorrect results. In this post, we’ll look into them.
Suppose you’re interviewing for a data engineering position, and you’re asked to aggregate some orders table by city. You start with the straight-forward SQL
select city, sum(price) revenue
from orders
group by city
order by revenue descNow, the interviewer will ask about possible performance problem, and you might answer that New York is a large city, so this query results in data skew. More specifically, all orders for the large city get shuffled to a single executor, which is then spends a lot of time aggregating them, while others wait.
One typical way to fix this problem is using salting. We add a random value to each row, use that random value to generate a group key that is better distributed, group by this key, and they group again by our original key. The SQL is still rather simple.
with salted as (
select city, city + '_' + rand() salted_city, price
from orders
),
pregrouped as (
select salted_city, first(city), price
from salted
group by salted_city
)
select city, price
from pregrouped
group by cityWhile this code is correct, it is not necessary. Spark knows that sum function can be partially computed,
so right when reading the orders table it will compute partial per-city sums. Then, it will shuffle these
partial sums, and the aggregation will have no performance problems.
But to continue the ‘interview’ story arc, let’s assume we’re asked to change sum to a more complicated
aggregating function, and we need to manually address the data skew. At this point, we run in a much
subtler problem with the code, and to understand it, we need to look the rand() is executed. This
is illustrated below.
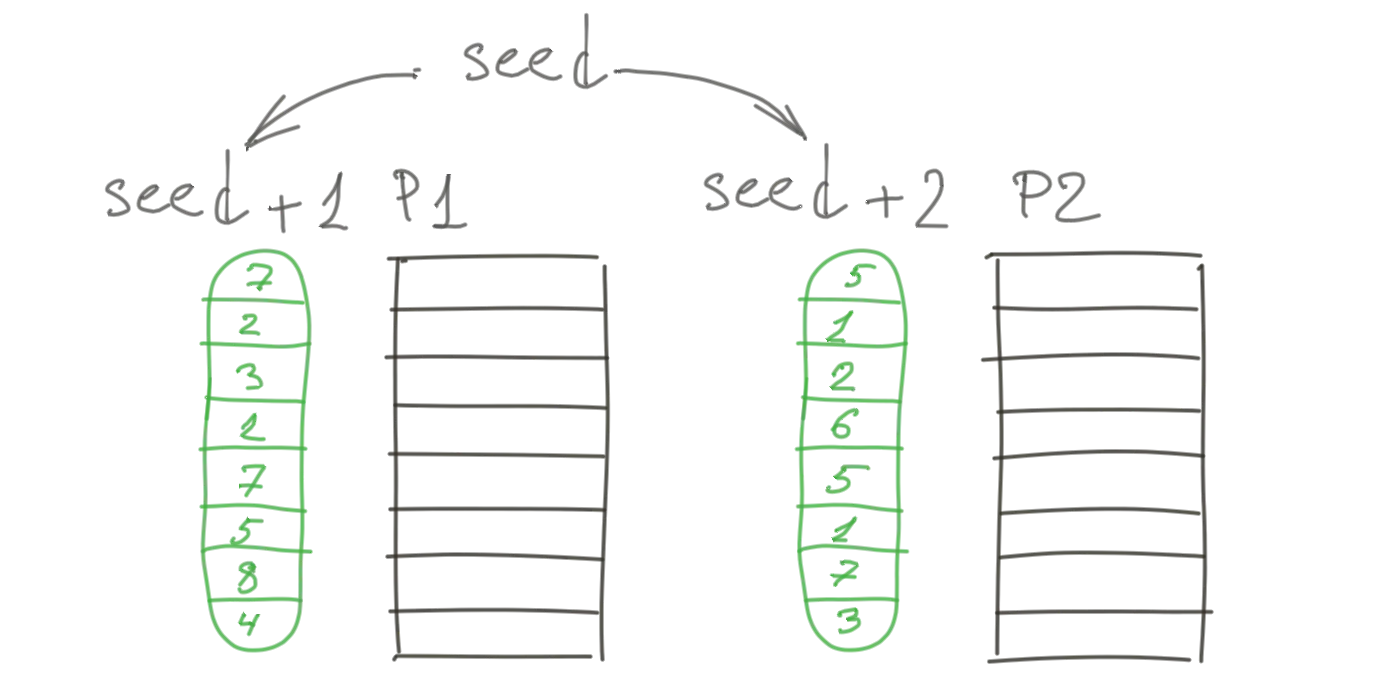
First, a global random seed is associated with the rand() function in our query. Second, for each partition,
a per-partition random seed is determined by adding global seed and the partition index. Finally, a pseudo-random
number generator starts with the partition seed and generates random numbers.
There is an obvious nondeterminism here. We haven’t provided any global seed, so Spark will pick a random value for the seed. Sort of double-random behaviour. We can solve this by providing the global seed explicitly, such as
with salted as (
select city, city + '_' + rand(17) salted_city, price
from orders
),
...The code now looks perfectly stable. If the entire job fails and is restarted, we’ll have the same global seed. If one executor fails, and one partition must be recomputed, the seed for that partition will be again the sum of global seed and partition index, and the sequence of pseudo-random numbers will be exactly the same.
But, what if ‘orders’ is not a simple table, but a view that is computed using joins? Let’s focus on one partition, and where it comes from.
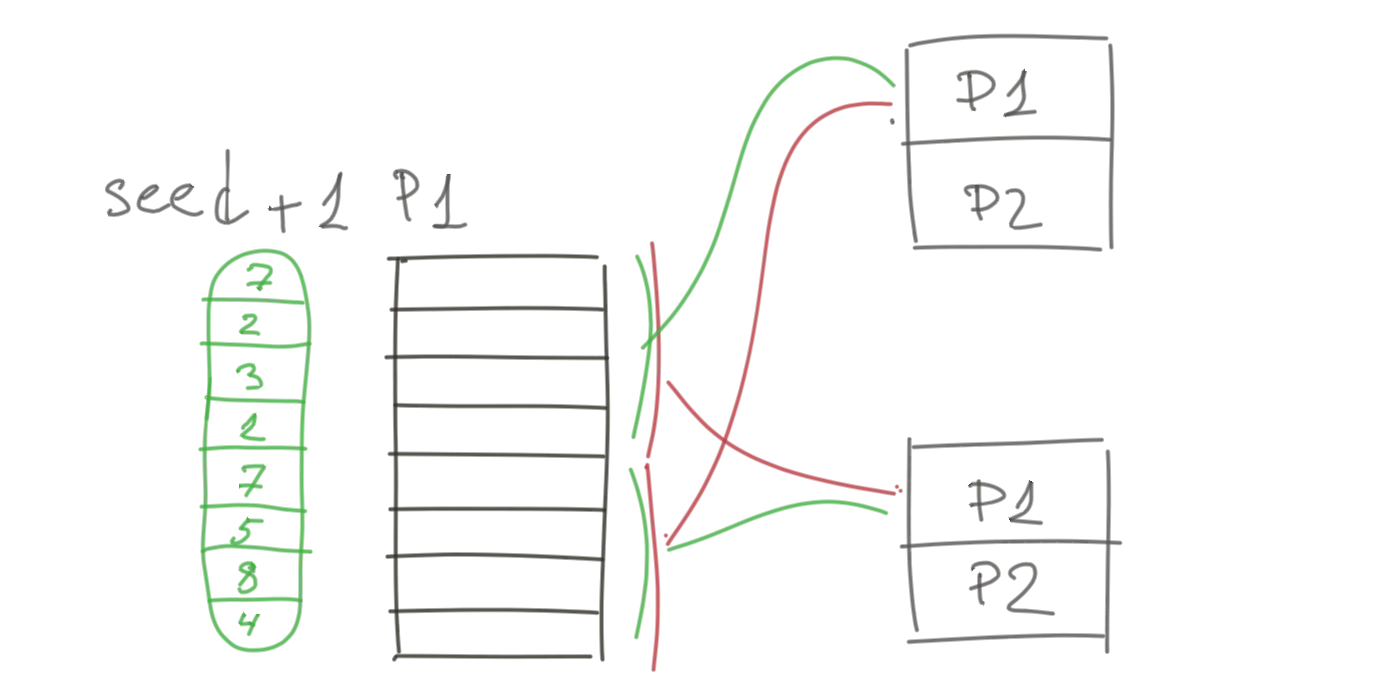
When our first partition is executed, it fetches corresponding pieces from the previous stage. However, they can arrive in random order, depending on whether previous stage partitions are located, system load, network conditions, and the moon. The set of rows is the same, but their order is not deterministic. Therefore, if our partition fails and is retried, the random numbers come in a predictable order, but they are attached to rows in a non-deterministic order.
After attaching random numbers, we group our dataset, which is another shuffle operation. But because our data is no longer deterministic, the shuffle operation itself becomes non-deterministic. One row can be duplicated, and another row can totally disappear.
Because this happens only on executor failure and task retries, this happens rarely. And because it affects only some rows, it’s not easy to detect, or test. Everything works fine in testing, and in production, the final result is a little bit off.
I would recommend to simply never use random to address data skew. Instead, there are few better ways:
- Give Spark adaptive query execution a chance, it might work.
- Use some existing column with high entropy, such as some id column
- If data skew happens during join, filter out the ‘special values’, such as nulls
- As the last resort, you can use checkpoint right after adding random column
But whatever you choose, please don’t use simple random. It will cause problems.